Tail Call Optimization in Elixir & Erlang - not as efficient and important as you probably think
(Automatic) Tail Call Optimization (TCO) is that great feature of Elixir and Erlang that everyone tells you about. It’s super fast, super cool and you should definitely always aim to make every recursive function tail-recursive. What if I told you that body-recursive functions can be faster and more memory efficient than their especially optimized tail-recursive counter parts? Seems unlikely, doesn’t it? After all every beginners book will mention TCO, tell you how efficient it is and that you should definitely use it. Plus, maybe you’ve tried body-recusion before in language X and your call stack blew up or it was horrendously slow. I did and I thought tail-recursive functions were always better than body-recursive. Until one day, by accident , I wrote a none tail-recursive function (so TCO didn’t apply to it). Someone told me and eagerly I replaced it with its tail-recursive counterpart. Then, I stopped for a second and benchmarked it - the results were surprising to say the least. Before we do a deep dive into the topic, let’s take a refresher on tail call optimization from Dave Thomas in Programming Elixir 1.2 (great book!):
(…) it ends up calling itself. In many languages, that adds a new frame to the stack. After a large number of messages, you might run out of memory. This doesn’t happen in Elixir, as it implements tail-call optimization. If the last thing a function does is call itself, there’s no need to make the call. Instead, the runtime simply jumps back to the start of the function. If the recursive call has arguments, then these replace the original parameters.
Well, let’s get into this :)
Writing a map implementation
So let’s write an implementation of the map function. One will be body-recursive, one will be tail-recursive. I’ll add another tail-recursive implementation using ++ but no reverse and one that just does not reverse the list in the end. The one that doesn’t reverse the list of course isn’t functionally equivalent to the others as the elements are not in order, but if you wrote your own function and don’t care about ordering this might be for you. In an update here I also added a version where the argument order is different, for more on this see the results and edit6.
Source: https://gist.github.com/pragtobgists/92fd7983dbf7d47f6d36d1cbf27495a2
File: my_map.ex
defmodule MyMap do
def map_tco(list, function) do
Enum.reverse _map_tco([], list, function)
end
defp _map_tco(acc, [head | tail], function) do
_map_tco([function.(head) | acc], tail, function)
end
defp _map_tco(acc, [], _function) do
acc
end
def map_tco_arg_order(list, function) do
Enum.reverse do_map_tco_arg_order(list, function, [])
end
defp do_map_tco_arg_order([], _function, acc) do
acc
end
defp do_map_tco_arg_order([head | tail], function, acc) do
do_map_tco_arg_order(tail, function, [function.(head) | acc])
end
def map_tco_concat(acc \\ [], list, function)
def map_tco_concat(acc, [head | tail], function) do
map_tco_concat(acc ++ [function.(head)], tail, function)
end
def map_tco_concat(acc, [], _function) do
acc
end
def map_body([], _func), do: []
def map_body([head | tail], func) do
[func.(head) | map_body(tail, func)]
end
def map_tco_no_reverse(list, function) do
_map_tco([], list, function)
end
end
map_body here is the function I originally wrote. It is not tail-recursive as the last operation in this method is the list append operation, not the call to map_body. Comparing it to all the other implementations, I’d also argue it’s the easiest and most readable as we don’t have to care about accumulators or reversing the list. Now that we have the code, let us benchmark the functions with benchee! Benchmark run on Elixir 1.3 with Erlang 19 on an i7-4790 on Linux Mint 17.3. Let’s just map over a large list and add one to each element of the list. We’ll also throw in the standard library implementation of map as a comparison baseline:
Source: https://gist.github.com/pragtobgists/70ef8dd38a86de48a3bf13091fbda27e
File: my_map_bench.exs
list = Enum.to_list(1..10_000)
map_fun = fn(i) -> i + 1 end
Benchee.run %{
"map tail-recursive with ++" =>
fn -> MyMap.map_tco_concat(list, map_fun) end,
"map with TCO reverse" =>
fn -> MyMap.map_tco(list, map_fun) end,
"stdlib map" =>
fn -> Enum.map(list, map_fun) end,
"map simple without TCO" =>
fn -> MyMap.map_body(list, map_fun) end,
"map with TCO new arg order" =>
fn -> MyMap.map_tco_arg_order(list, map_fun) end,
"map TCO no reverse" =>
fn -> MyMap.map_tco_no_reverse(list, map_fun) end
}, time: 10, warmup: 10
File: results
tobi@happy ~/github/elixir_playground $ mix run bench/tco_blog_post_detailed.exs
Benchmarking map tail-recursive with ++...
Benchmarking map TCO no reverse...
Benchmarking stdlib map...
Benchmarking map with TCO new arg order...
Benchmarking map simple without TCO...
Benchmarking map with TCO reverse...
Name ips average deviation median
map simple without TCO 6015.31 166.24μs (±6.88%) 163.00μs
stdlib map 5815.97 171.94μs (±11.29%) 163.00μs
map with TCO new arg order 5761.46 173.57μs (±10.24%) 167.00μs
map TCO no reverse 5566.08 179.66μs (±6.39%) 177.00μs
map with TCO reverse 5262.89 190.01μs (±9.98%) 182.00μs
map tail-recursive with ++ 8.66 115494.33μs (±2.86%) 113537.00μs
Comparison:
map simple without TCO 6015.31
stdlib map 5815.97 - 1.03x slower
map with TCO new arg order 5761.46 - 1.04x slower
map TCO no reverse 5566.08 - 1.08x slower
map with TCO reverse 5262.89 - 1.14x slower
map tail-recursive with ++ 8.66 - 694.73x slower
(The benchmarking was actually done bythis a little more verbose but equivalent script so it generates the CSV ouput and console output on the same run using benchee’s slightly more verbose interface. Feature to make that possible with the nicer interface is planned ;) ) For the more visual here is also a graph showcasing the results (visualized using benchee_csv): 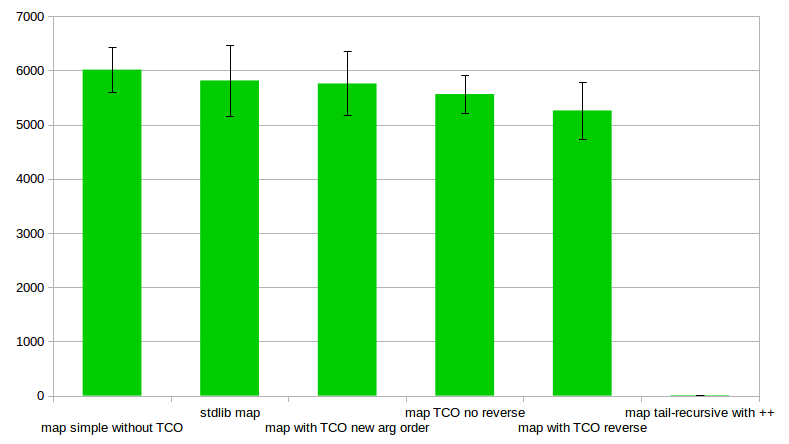 Graphing iterations per second (higher is better) So what do we see? The body-recursive function seems to be as fast as the version from standard library. The reported values are faster, but well within the margin of error. Plus the median of the two is the same while standard deviation is higher for the standard library version. This hints at the possibility that the worse average may be through some outliers (resulting f.ex. from Garbage Collection). The tail-recursive version with
Graphing iterations per second (higher is better) So what do we see? The body-recursive function seems to be as fast as the version from standard library. The reported values are faster, but well within the margin of error. Plus the median of the two is the same while standard deviation is higher for the standard library version. This hints at the possibility that the worse average may be through some outliers (resulting f.ex. from Garbage Collection). The tail-recursive version with ++ is VERY SLOW but that’s because appending with ++ so frequently is a bad idea as it needs to go to the end of the linked list every time around (O(n)). But that’s not the main point. The main point is that the tail-recursive version is about 14% slower! Even the tail-recursive version that doesn’t reverse the list is slower than the body-recursive implementation! Here seems like a good point to interject and mention that it was brought up in the comments (see edit11) that for significantly larger lists tail-recursive implementations get faster again. You can check out the
Source: https://gist.github.com/PragTob/d07b88d9c5949d73e2ccc34657955699
File: benchmark_result
tobi@happy ~/github/elixir_playground $ mix run bench/my_map_bench.exs
Erlang/OTP 19 [erts-8.1] [source-4cc2ce3] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false]
Elixir 1.3.4
Benchmark suite executing with the following configuration:
warmup: 10.0s
time: 30.0s
parallel: 1
Estimated total run time: 360.0s
Benchmarking exactly_like_my_map...
Benchmarking map TCO no reverse...
Benchmarking map simple without TCO...
Benchmarking map with TCO reverse...
Benchmarking map with TCO reverse at acc...
Benchmarking map with TCO reverse new acc...
Benchmarking map with TCO reverse new arg order...
Benchmarking my_map...
Benchmarking stdlib map...
Name ips average deviation median
map TCO no reverse 5.26 190.18 ms ±10.81% 194.38 ms
map with TCO reverse new arg order 4.61 216.98 ms ±12.75% 206.13 ms
my_map 4.60 217.39 ms ±13.01% 206.47 ms
exactly_like_my_map 4.57 218.65 ms ±13.80% 205.51 ms
map with TCO reverse at acc 4.25 235.07 ms ±12.27% 220.51 ms
map with TCO reverse 4.24 235.68 ms ±12.37% 222.78 ms
map with TCO reverse new acc 4.24 236.06 ms ±11.95% 225.56 ms
map simple without TCO 2.67 374.34 ms ±4.88% 372.32 ms
stdlib map 2.67 374.75 ms ±5.48% 373.14 ms
Comparison:
map TCO no reverse 5.26
map with TCO reverse new arg order 4.61 - 1.14x slower
my_map 4.60 - 1.14x slower
exactly_like_my_map 4.57 - 1.15x slower
map with TCO reverse at acc 4.25 - 1.24x slower
map with TCO reverse 4.24 - 1.24x slower
map with TCO reverse new acc 4.24 - 1.24x slower
map simple without TCO 2.67 - 1.97x slower
stdlib map 2.67 - 1.97x slower
. What is highly irritating and surprising to me is that the tail-recursive function with a slightly different argument order is significantly faster than my original implementation, almost 10%. And this is not a one off - it is consistently faster across a number of runs. You can see more about that implementation in edit6 below. Thankfully José Valim chimed in about the argument order adding the following:
The order of arguments will likely matter when we generate the branching code. The order of arguments will specially matter if performing binary matching. The order of function clauses matter too although I am not sure if it is measurable (if the empty clause comes first or last).
Now, maybe there is a better tail-recursive version (please tell me!) but this result is rather staggering but repeatable and consistent. So, what happened here?
An apparently common misconception
That tail-recursive functions are always faster seems to be a common misconception - common enough that it made the list of Erlang Performance Myths as “Myth: Tail-Recursive Functions are Much Faster Than Recursive Functions”! (Note: this section is currently being reworked so the name might change/link might not lead to it directly any more in the near-ish future) To quote that:
A body-recursive list function and a tail-recursive function that calls lists:reverse/1 at the end will use the same amount of memory. lists:map/2, lists:filter/2, list comprehensions, and many other recursive functions now use the same amount of space as their tail-recursive equivalents. So, which is faster? It depends. On Solaris/Sparc, the body-recursive function seems to be slightly faster, even for lists with a lot of elements. On the x86 architecture, tail-recursion was up to about 30% faster
The topic also recently came up on the erlang-questions mailing list again while talking about the rework of the aforementioned Erlang performance myths site (which is really worth the read!). In it Fred Hebert remarks (emphasis added by me):
In cases where all your function does is build a new list (or any other accumulator whose size is equivalent to the number of iterations and hence the stack) such as map/2 over nearly any data structure or say zip/2 over lists, body recursion may not only be simpler, but also faster and save memory over time.
He also has his own blog post on the topic.
But won’t it explode?
I had the same question. From my experience with the clojure koans I expected the body-recursive function to blow up the call stack given a large enough input. But, I didn’t manage to - no matter what I tried. Seems it is impossible as the BEAM VM, that Erlang and Elixir run in, differs in its implementation from other VMs, the body recursion is limited by RAM:
Erlang has no recursion limit. It is tail call optimised. If the recursive call is not a tail call it is limited by available RAM
Memory consumption
So what about memory consumption? Let’s create a list with one hundred million elements (100_000_000) and map over it measuring the memory consumption. When this is done the tail-recursive version takes almost 13 Gigabytes of memory while the body-recursive version takes a bit more than 11.5 Gigabytes. Details can be found in
Source: https://gist.github.com/pragtobgists/ed0af0d76eed7dce35b5fe5edca03bd1
File: no_tco_list.exs
list = Enum.to_list(1..100_000_000)
MyMap.map_body(list, fn(i) -> i + 1 end)
File: tco_list.exs
list = Enum.to_list(1..100_000_000)
MyMap.map_tco(list, fn(i) -> i + 1 end)
File: z_results
tobi@happy ~/github/elixir_playground $ /usr/bin/time -v mix run scripts/tco_list.exs
Command being timed: "mix run scripts/tco_list.exs"
User time (seconds): 10.00
System time (seconds): 1.21
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:11.22
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 13052492
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 33
Minor (reclaiming a frame) page faults: 112706
Voluntary context switches: 20743
Involuntary context switches: 1006
Swaps: 0
File system inputs: 13088
File system outputs: 24
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
tobi@happy ~/github/elixir_playground $ /usr/bin/time -v mix run scripts/no_tco_list.exs
Command being timed: "mix run scripts/no_tco_list.exs"
User time (seconds): 9.02
System time (seconds): 0.83
Percent of CPU this job got: 100%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:09.81
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 11511968
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 1
Minor (reclaiming a frame) page faults: 40774
Voluntary context switches: 20006
Involuntary context switches: 122
Swaps: 0
File system inputs: 8
File system outputs: 24
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
. Why is that? Well most likely here with the large list it is because the tail recursive version needs to create a new reversed version of the accumulator to return a correct result.
Body-recursive functions all the time now?
So let’s recap, the body-recursive version of map is:
- faster
- consumes less memory
- easier to read and maintain
So why shouldn’t we do this every time? Well there are other examples of course. Let’s take a look at a very dumb function deciding whether a number is even (implemented as a homage to this clojure kaons exercise that showed how the call stack blows up in Clojure without recur):
Source: https://gist.github.com/pragtobgists/4e38f696912d01882f5b789e9d6c076b
File: number.ex
defmodule Number do
def is_even?(0), do: true
def is_even?(n) do
!is_even?(n - 1)
end
def is_even_tco?(n, acc \\ true)
def is_even_tco?(0, acc), do: acc
def is_even_tco?(n, acc) do
is_even_tco?(n - 1, !acc)
end
end
File: number_is_even_bench.exs
number = 10_000_000
Benchee.run %{
"is_even?" => fn -> Number.is_even?(number) end,
"is_even_tco?" => fn -> Number.is_even_tco?(number) end,
}
File: results
tobi@happy ~/github/elixir_playground $ mix run bench/is_even.exs
Benchmarking is_even?...
Benchmarking is_even_tco?...
Name ips average deviation median
is_even? 10.26 97449.21μs (±0.50%) 97263.00μs
is_even_tco? 9.39 106484.48μs (±0.09%) 106459.50μs
Comparison:
is_even? 10.26
is_even_tco? 9.39 - 1.09x slower
The tail-recursive version here is still 10% slower. But what about memory? Running the function with one hundred million as input takes 41 Megabyte for the tail-recursive version (mind you, this is the whole elixir process) butalmost 6.7 Gigabyte for the body-recursive version. Also, for that huge input the tail-recursive version took 1.3 seconds, while the body-recursive function took 3.86 seconds. So for larger inputs, it is faster. Stark contrast, isn’t it? That’s most likely because this time around there is no huge list to be carried around or accumulated - just a boolean and a number. Here the effect that the body-recursive function needs to save its call stack in the RAM has a much more damaging effect, as it needs to call itself one hundred million times. Rerunning the map implementation with a significantly larger list, the tail-recursive versions also
Source: https://gist.github.com/PragTob/d07b88d9c5949d73e2ccc34657955699
File: benchmark_result
tobi@happy ~/github/elixir_playground $ mix run bench/my_map_bench.exs
Erlang/OTP 19 [erts-8.1] [source-4cc2ce3] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false]
Elixir 1.3.4
Benchmark suite executing with the following configuration:
warmup: 10.0s
time: 30.0s
parallel: 1
Estimated total run time: 360.0s
Benchmarking exactly_like_my_map...
Benchmarking map TCO no reverse...
Benchmarking map simple without TCO...
Benchmarking map with TCO reverse...
Benchmarking map with TCO reverse at acc...
Benchmarking map with TCO reverse new acc...
Benchmarking map with TCO reverse new arg order...
Benchmarking my_map...
Benchmarking stdlib map...
Name ips average deviation median
map TCO no reverse 5.26 190.18 ms ±10.81% 194.38 ms
map with TCO reverse new arg order 4.61 216.98 ms ±12.75% 206.13 ms
my_map 4.60 217.39 ms ±13.01% 206.47 ms
exactly_like_my_map 4.57 218.65 ms ±13.80% 205.51 ms
map with TCO reverse at acc 4.25 235.07 ms ±12.27% 220.51 ms
map with TCO reverse 4.24 235.68 ms ±12.37% 222.78 ms
map with TCO reverse new acc 4.24 236.06 ms ±11.95% 225.56 ms
map simple without TCO 2.67 374.34 ms ±4.88% 372.32 ms
stdlib map 2.67 374.75 ms ±5.48% 373.14 ms
Comparison:
map TCO no reverse 5.26
map with TCO reverse new arg order 4.61 - 1.14x slower
my_map 4.60 - 1.14x slower
exactly_like_my_map 4.57 - 1.15x slower
map with TCO reverse at acc 4.25 - 1.24x slower
map with TCO reverse 4.24 - 1.24x slower
map with TCO reverse new acc 4.24 - 1.24x slower
map simple without TCO 2.67 - 1.97x slower
stdlib map 2.67 - 1.97x slower
. See edit11.
So, what now?
Tail-recursive functions still should be faster and more efficient for many or most use cases. Or that’s what I believe through years of being taught that tail call optimization leads to the fastest recursive functions ;). This post isn’t to say that TCO is bad or slow. It is here to say and highlight that there are cases where body-recursive functions are faster and more efficient than tail-recursive functions. I’m also still unsure why the tail-recursive function that does not reverse the list is still slower than the body-recursive version - it might be because it has to carry the accumulator around. Maybe we should also take a step back in education and teaching and be more careful not to overemphasize tail call optimization and with it tail-recursive functions. Body-recursive functions can be a viable, or even superior, alternative and they should be presented as such. There are, of course, cases where writing tail-recursive functions is absolutely vital, as Robert Virding, creator of Erlang, rightfully highlights:
No, the main case where is TCO is critical is in process top-loops. These functions never return (unless the process dies) so they will build up stack never to release it. Here you have to get it right. There are no alternatives. The same applies if you top-loop is actually composed of a set of mutually calling functions. There there are no alternatives. Sorry for pushing this again, and again, but it is critical.

But what does this teach us in the end? Don’t take your assumptions stemming from other programming environments for granted. Also, don’t assume - always proof. So let’s finish with the closing words of the Erlang performance myths section on this:
So, the choice is now mostly a matter of taste. If you really do need the utmost speed, you must measure. You can no longer be sure that the tail-recursive list function always is the fastest.
edit1: there previously was a bug in is_even_tco? with a missing not, not caught by my tests as they were calling the wrong function :( Thanks to Puella for notifying me. edit2/addendum: (see next edit/update) It was pointed out at lobste.rs that running it in an erlang session thebody-recursive function was significantly slower than the tco version. Running what I believe to be equivalent code in Elixir and Erlang it seems that the Erlang map_body version is significantly slower than in Elixir (2 to 3 times by the looks of it). I’d need to run it with an Erlang benchmarking tool to confirm this, though. edit3/addendum2: The small tries mentioned in the first addendum were run in the shell which is not a great idea, using my little erlang knowledge I made something that compiled that “benchmark” and map_body is as fast/faster again thread. Benchmarking can be fickle and wrong if not done right, so would still look forward to run this in a proper Erlang benchmarking tool or use Benchee from Erlang. But no time right now :( edit4: Added comment from Robert Virding regarding process top loops and how critical TCO is there. Thanks for reading, I’m honoured and surprised that one of the creators of Erlang read this :) His full post is of course worth a read. edit5: Following the rightful nitpick I don’t write “tail call optimized” functions any more but rather “tail-recursive” as tail call optimization is more of a feature of the compiler and not directly an attribute of the function edit6: Included another version in the benchmark that swaps the argument order so that the list stays the first argument and the accumulator is the last argument. Surprisingly (yet again) this version is constantly faster than the other tail-recursive implementation but still slower than body recursive. I want to thank Paweł for pointing his version out in the comments. The reversed argument order was the only distinguishing factor I could make out in his version, not the assignment of the new accumulator.I benchmarked all the different variants multiple times. It is consistently faster, although I could never reproduce it being the fastest. For the memory consumption example it seemed to consume about 300MB less than the original tail-recursive function and was a bit faster. Also since I reran it either way I ran it with the freshly released Elixir 1.3 and Erlang 19. I also increased the runtime of the benchmark as well as the warmup (to 10 and 10) to get more consistent results overall. And I wrote a new benchmarking script so that the results shown in the graph are from the same as the console output. edit7: Added a little TCO intro as it might be helpful for some :) edit8: In case you are interested in what the bytecode looks like, I haven’t done it myself (not my area of expertise - yet) there is a
Source: https://gist.github.com/sasa1977/73274c2be733b5321ace
File: ex_to_asm.ex
[{_, beam}] = Code.compile_string("""
defmodule Test do
def tail_call(x) do
tail_call(x)
end
def non_tail_call(x) do
1 + tail_call(x)
end
end
""")
{:ok,{_,[{:abstract_code,{_,abstract_code}}]}} = :beam_lib.chunks(beam,[:abstract_code])
{:ok, module, asm} = :compile.forms(abstract_code, [:to_asm])
IO.inspect(asm)
File: output.txt
...
{:function, :non_tail_call, 1, 8,
[{:label, 7}, {:line, [{:location, 'nofile', 10}]},
{:func_info, {:atom, Test}, {:atom, :non_tail_call}, 1}, {:label, 8},
{:allocate, 0, 1}, {:line, [{:location, 'nofile', 11}]},
{:call, 1, {:f, 10}}, {:line, [{:location, 'nofile', 11}]}, <- non_tail call
{:gc_bif, :+, {:f, 0}, 1, [integer: 1, x: 0], {:x, 0}}, {:deallocate, 0},
:return]},
...
{:function, :tail_call, 1, 10,
[{:label, 9}, {:line, [{:location, 'nofile', 2}]},
{:func_info, {:atom, Test}, {:atom, :tail_call}, 1}, {:label, 10},
{:test, :is_lt, {:f, 11}, [integer: 0, x: 0]}, {:call_only, 1, {:f, 10}},
{:label, 11}, {:call_only, 1, {:f, 10}}]}, <- tail call
edit9: Added José’s comment about the argument order, thanks for reading and commenting! :) edit10: Added CPU and OS information :) edit11: It was pointed out in the comments that the performance characteristics might differ for larger lists. And it does, taking 1000 times as many elements (10_000_000) all tail-recursive versions are
Source: https://gist.github.com/PragTob/d07b88d9c5949d73e2ccc34657955699
File: benchmark_result
tobi@happy ~/github/elixir_playground $ mix run bench/my_map_bench.exs
Erlang/OTP 19 [erts-8.1] [source-4cc2ce3] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false]
Elixir 1.3.4
Benchmark suite executing with the following configuration:
warmup: 10.0s
time: 30.0s
parallel: 1
Estimated total run time: 360.0s
Benchmarking exactly_like_my_map...
Benchmarking map TCO no reverse...
Benchmarking map simple without TCO...
Benchmarking map with TCO reverse...
Benchmarking map with TCO reverse at acc...
Benchmarking map with TCO reverse new acc...
Benchmarking map with TCO reverse new arg order...
Benchmarking my_map...
Benchmarking stdlib map...
Name ips average deviation median
map TCO no reverse 5.26 190.18 ms ±10.81% 194.38 ms
map with TCO reverse new arg order 4.61 216.98 ms ±12.75% 206.13 ms
my_map 4.60 217.39 ms ±13.01% 206.47 ms
exactly_like_my_map 4.57 218.65 ms ±13.80% 205.51 ms
map with TCO reverse at acc 4.25 235.07 ms ±12.27% 220.51 ms
map with TCO reverse 4.24 235.68 ms ±12.37% 222.78 ms
map with TCO reverse new acc 4.24 236.06 ms ±11.95% 225.56 ms
map simple without TCO 2.67 374.34 ms ±4.88% 372.32 ms
stdlib map 2.67 374.75 ms ±5.48% 373.14 ms
Comparison:
map TCO no reverse 5.26
map with TCO reverse new arg order 4.61 - 1.14x slower
my_map 4.60 - 1.14x slower
exactly_like_my_map 4.57 - 1.15x slower
map with TCO reverse at acc 4.25 - 1.24x slower
map with TCO reverse 4.24 - 1.24x slower
map with TCO reverse new acc 4.24 - 1.24x slower
map simple without TCO 2.67 - 1.97x slower
stdlib map 2.67 - 1.97x slower
. edit12: Updated to reflect newer Benchee API as the old API with lists of tuples doesn’t work anymore :)